JPA 도입 이전 개발 환경
● 전통적으로 Java 기반의 데이터베이스 연동 애플리케이션은 JDBC와 SQL을 직접 다루는 방식으로 구축되었다.
● 우리가 만든 객체를 관계형 데이터베이스에 보관하고, 이 데이터를 사용 할 때는 다시 객체로 바꾸어 사용했다.
● 즉 자바 객체를 SQL로 바꾸고, SQL을 자바 객체로 바꾸는 과정을 직접 반복한다.
● 이처럼 객체와 데이터베이스 사이의 매핑을 수작업으로 처리하는 방식은, 시스템이 커질수록 반복 작업이 많아진다.
● 오류 가능성 또한 높아지며, 유지 보수를 어렵게 만들었다.
SQL에 종속된 개발 구조의 문제
● 전통적인 개발 방식에서는 도메인 모델이 아닌, SQL이 중심이 된다.
● 도메인 모델이 복잡해질수록 SQL과 자바 코드 간의 간극이 커진다.
● SQL이 하드 코딩 되어 있으면 로직 변경 시 전체 코드를 찾아 수정해야 하며, IDE의 리팩토링 지원을 받기 어렵다.
● SELECT, INSERT, UPDATE, DELETE 같은 단순한 쿼리를 매번 작성해야 한다.
● 개발 중간에 필드가 추가되면 관련된 모든 쿼리를 직접 수정해야 한다.
public class Member {
private String id;
private string name;
+ private String email;
}INSERT INTO MEMBER(ID, NAME, +EMAIL) VALUES(...)
SELECT ID, NAME, +EMAIL FROM MEMBER
UPDATE MEMBER SET ... +EMAIL = ...객체지향과 관계형 데이터베이스 간 패러다임 불일치 문제
연관관계: 참조 vs 외래키
class Team {
Long id;
String name;
}
class Member {
Long id;
String name;
Team team;
}
● 객체는 참조(Reference)를 통해 관계를 표현한다.
● 예를 들어 Member 객체는 Team 객체를 필드로 갖는다.
class Member {
Long id;
String name;
Long teamId;
}
● 그러나 관계형 데이터베이스는 team_id 같은 외래키(Foreign Key)로 관계를 표현한다.
● 즉 객체의 참조를 SQL에서는 외래키 값으로 바꾸어야 한다.
● 사용자를 조회할 때 조회 결과를 각 객체에 저장하고, 참조로 관계를 설정하는 작업을 매번 거쳐야 한다.
public Member findById(Long memberId) {
// 쿼리 실행 결과 가져오기
SELECT M.*, T.* FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.ID
// 쿼리 결과 중 멤버 관련 정보 객체에 저장
Member member = new Member();
set...
// 팀 관련 정보 저장
Team team = new Team();
set...
// 회원 팀 관계 설정
member.setTeam(team);
return member;
}
탐색 기반 vs JOIN 기반
● 객체는 연관된 객체를 메서드 호출로 탐색한다. member.getTeam().getName()
● SQL은 연관된 데이터를 조회하기 위해 명시적인 JOIN 구문을 사용해야 한다.
● 따라서 SQL은 작성한 쿼리에 따라 탐색 범위가 결정된다.
SELECT M.*, T.* FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.ID
● 이렇게 작성 되었을 때는 member.getTeam()은 결과가 있지만, member.getOrder()는 null이다.
class MemberService {
...
public void process(Long memberId) {
Member member = memberRepository.find(memberId);
member.getTeam() ???
member.getOrder().getDelivery() ???
}
}
● 쿼리를 확인하기 전까지는 연관 객체가 존재하는지 알 수가 없다.
● 이처럼 엔티티 신뢰 문제가 발생한다.
● 연관 객체가 존재하는지 서비스 로직만 보고는 알 수가 없다.
● 계층의 아키텍처라는 것은 내가 다음 계층을 믿고 사용할 수 있어야 한다.
● 그러나 서비스 로직을 작성하는데 memberRepository의 find 코드를 확인해야만 getTeam, getOrder 등 존재를 확신할 수 있다.
// 멤버만 조회
memberRepository.getMember();
// 멤버와 팀 조회
memberRepository.getMemberWithTeam();
// 멤버, 주문, 배송 조회
memberRepsitory.getMemberWithOrderWithDelivery();
● 그렇다고 전체 케이스에 대한 쿼리를 다 작성하여, 모든 연관 객체를 미리 로딩할 수는 없다.
● 메모리에 사용하지도 않는 데이터를 무조건 올려야 하는 것도 문제다.
● 따라서 진정한 의미의 계층 분할이 어려워진다.
계층 구조 vs 테이블 정규화

● 객체는 상속과 같이 계층적이고 복잡한 구조를 가질 수 있다.
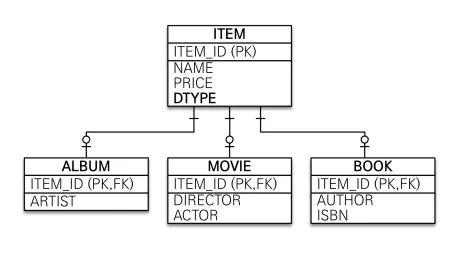
● RDB는 상속을 표현하기 어렵기 때문에, 여러 테이블로 분해하여 JOIN으로 대응한다.
● Album 객체를 저장하려면 다음 과정을 거친다.
○ ITEM, ALBUM 테이블에 저장해야 하는 필드가 다르므로 객체를 분해해야 한다.
○ INSERT INTO ITEM …
○ INSERT INTO ALBUM …
● Album을 조회하는 과정은 어떨까?
○ ITEM, ALBUM JOIN SQL을 작성한다.
○ Item, Album 객체를 생성하고 조회한 결과를 분해하여 각 객체에 set한다.
● Album 뿐만 아니라 Movie, Book 모든 케이스에 대해 CRUD를 만들어야 한다.
● 이렇게 복잡하기 때문에 DB에 저장할 객체에는 상속 관계를 쓰지 않는다.
비교 문제
Long memberId = 1L;
Member member1 = memberRepository.findById(memberId);
Member member2 = memberRepository.findById(memberId);
member1 == member2 // false
● memberId가 1인 멤버는 유일하므로 동등 비교에서 같아야 한다.
● 그러나 객체 참조 값이 다르기 때문에 같지 않다.
객체지향적으로 설계하면 할수록, 예를 들어 상속 관계나 다양한 참조, 연관 관계가 복잡해질수록, 이를 관계형 데이터베이스에 맞춰 매핑하는 작업은 그만큼 더 어려워진다.
객체지향적인 모델링이 강화될수록 RDB와의 구조적 괴리는 커지고, 수작업 매핑의 복잡도는 기하급수적으로 증가하게 된다.
JPA란 무엇인가?
● JPA(Java Persistence API)는 ORM(Object Relational Mapping) 기술의 자바 표준 인터페이스로, 객체와 테이블 사이의 매핑을 자동으로 처리하고, 도메인 모델 중심 개발을 가능하게 해준다.
● 객체는 객체대로 설계하고, 관계형 DB는 관계형 DB대로 설계하고, ORM 프레임워크가 중간에서 매핑해준다.
● JPA는 ORM인 Hibernate 오픈소스에서 출발했다.
● 구현체로 거의 Hibernate사용하는데, Hibernate를 만든 개발자가 자바 표준으로 JPA를 만들었으니 어떻게보면 당연한 일이다.
JPA를 사용해야 하는 이유
SQL 중심에서 객체 중심으로 개발
● 개발자가 데이터베이스에 의존적인 SQL 쿼리를 직접 작성하는 대신, 객체를 통해 데이터를 관리할 수 있게 된다.
데이터베이스 벤더 독립성
● JPA는 추상화 계층을 제공하여 특정 데이터베이스 벤더에 종속되지 않는다.
● MYSQL에서 PostgreSQL로 변경하더라도 코드를 크게 변경할 필요가 없다.
● 하지만 SQL 표준을 지키지 않는 특정 데이터베이스만의 고유한 기능이 존재한다.
● 예를 들어 페이징의 경우 MySQL은 LIMIT, Oracle은 ROWNUM을 사용한다.
● DB마다 SQL 문법, 함수, 페이징 방식, 데이터 타입 등의 차이점을 Dialect 클래스를 통해 해결한다.

생산성
| 저장 | em.persist(member) |
| 조회 | Member member = em.find(Member.class, memberId) |
| 수정 | member.setName(”NAME”) |
| 삭제 | em.remove(member) |
● 위와 같은 코드를 사용하면 JPA가 자동으로 그에 맞는 쿼리로 변환해서 보낸다.
유지보수
@Entity
public class Member {
private String id;
private string name;
+ private String email;
}
● 개발 중간에 필드가 추가되어도 모든 쿼리를 수정할 필요가 없다.
● JPA Entity에 필드만 추가하면 관련 쿼리는 자동으로 JPA가 처리한다.
패러다임 불일치 해결
상속
● 저장의 경우 개발자가 em.persist(album)만 작성하면 ITEM, ALBUM INSERT 쿼리는 JPA가 처리한다.
● 조회의 경우 em.find(Album.class, albumId)만 하면 ITEM, ALBUM JOIN 쿼리는 JPA가 처리한다.
연관관계와 객체 그래프 탐색
member.setTeam(team);
em.persist(member);
● 외래키가 아닌 객체를 set하여 참조로 연관관계를 맺게 된다.
Member member = em.find(Member.class, memberId);
Team team = member.getTeam();
● 객체를 조회하면 JPA가 JOIN 쿼리를 처리한다.
신뢰할 수 있는 엔티티, 계층
class MemberService {
...
public void process(Long memberId) {
Member member = memberRepository.find(memberId);
member.getTeam();
member.getOrder().getDelivery();
}
}
● JOIN 쿼리는 JPA가 알아서 처리하기 때문에 자유롭게 객체 그래프를 탐색할 수 있다.
비교하기
Long memberId = 1L;
Member member1 = memberRepository.findById(memberId); // SQL
Member member2 = memberRepository.findById(memberId); // Cache
member1 == member2 // true
● 같은 트랜잭션 안에서 조회한 엔티티는 동일함을 보장한다.
JPA의 성능 최적화 기능
1차 캐시와 동일성 보장
● 같은 트랜잭션 안에서 조회한 엔티티는 동일하므로 약간의 성능이 향상된다.
● DB Isolation Level이 Read Committed여도 애플리케이션 Repeatable Read를 보장한다.
Isolation Level - 트랜잭션 격리 수준 깊게 이해하기
InnoDB 스토리지 엔진을 사용하는 mysql 기준으로 정리한다. 먼저 MVCC와 undo log, read view에 대한 이해가 필요하다. MVCC 깊게 이해하기: Undo Log 기반 다중 버전 동시 제어의 원리InnoDB 스토리지 엔진을
cactuslog.tistory.com
DB 격리수준 참고
트랜잭션을 지원하는 쓰기 지연
tx.begin();
em.persist(memberA);
em.persist(memberA);
em.persist(memberA);
// 여기까지 INSERT 쿼리를 DB에 보내지 않는다.
tx.commit(); // commit하는 순간 DB에 INSERT SQL을 모아서 보낸다.
● 트랜잭션을 commit할 때까지 INSERT SQL을 모아서 JDBC BATCH 기능을 사용해서 한번에 전송한다.
지연(Lazy) 로딩과 즉시(Eager) 로딩
Member member = em.find(Member.class, memberId); -> SELECT * FROM MEMEBER
Team team = member.getTeam();
String name = team.getName(); -> SELECT * FROM TEAM
● 지연 로딩: 객체가 실제 사용될 때 로딩
Member member = em.find(Member.class, memberId);
-> SELECT M.*, T.* FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.ID
● 즉시 로딩: JOIN SQL로 한번에 연관된 객체까지 미리 조회
JPA가 알아서 처리해주니까 쿼리를 몰라도 될까?
ORM은 중간에서 매핑해주는 역할이기 때문에 정확하게 사용하려면 객체지향, RDB를 둘 다 잘 이해해야한다.
참고: 김영한의 스프링 부트와 JPA 실무 완전 정복 로드맵
김영한의 스프링 부트와 JPA 실무 완전 정복 로드맵 로드맵 - 인프런
Java, JPA 스킬을 학습할 수 있는 개발 · 프로그래밍 로드맵을 인프런에서 만나보세요.
www.inflearn.com
'springboot > jpa' 카테고리의 다른 글
| JPA 기본키(PK) 매핑 전략 (0) | 2025.06.23 |
|---|---|
| JPA 필드와 컬럼 매핑 (0) | 2025.06.23 |
| JPA DB 스키마 자동 생성 이상과 현실 (0) | 2025.06.22 |
| JPA 클래스와 테이블 매핑 @Entity, @Table (1) | 2025.06.22 |
| JPA 영속성 관리 (1) | 2025.06.20 |



