InnoDB 스토리지 엔진을 사용하는 mysql 기준으로 정리한다.
MVCC (Multi Version Concurrency Control)
여러 트랜잭션이 동시에 같은 데이터를 조회하거나 수정할 때
서로 간섭하지 않고도 일관된 데이터를 읽을 수 있게 해주는 동시성 제어 기술
각 트랜잭션은 자신만의 스냅샷을 유지하며, 다른 트랜잭션이 데이터를 변경하더라도 스냅샷 기준으로 데이터를 읽는다.
여기서 스냅샷은 ReadView이며 구조는 다음과 같다.
| 필드 | 설명 |
| low_limit_id | low_limit_id 이상의 트랜잭션이 만든 변경 내용은 절대 보이면 안된다. 즉 이 값은 보이지 않는 트랜잭션의 시작선이다. low_limit_id 이상이 변경한 row는 undo log로 복원하거나 무시한다. |
| up_limit_id | up_limit_id보다 작은 트랜잭션들이 만든 변경은 전부 보여도 된다. 즉 보여줄 수 있는 과거 트랜잭션의 경계선이다. up_limit_id보다 작은 trx_id는 ReadView에서 커밋된 과거로 간주한다. |
| trx_ids | 현재 트랜잭션이 시작할 때 이미 실행 중이던 트랜잭션들의 id 목록. 단 내 트랜잭션은 제외. 이 목록에 있는 trx_id가 만든 변경은 보이면 안된다. 이 배열은 ReadView 생성 시 아직 커밋되지 않은 다른 트랜잭션들을 의미한다. |
| creator_trx_id | 이 ReadView를 만든 트랜잭션 id |
일관된 READ를 제공하기 위해 Lock을 사용해도 되지만 처리 성능이 안 좋아지는 문제가 있다.
Lock을 사용하지 않으면서 동시성 문제를 해결하기 위해 InnoDB 에서는 MVCC를 사용한다.
MVCC의 핵심은 동일한 Row의 여러 버전을 관리하여, 트랜잭션마다 자신에게 일관된 데이터를 보여주는 것이다.
InnoDB는 실제 테이블(Row)에는 가장 최신 버전만 저장하고, 변경 이전의 데이터는 Undo Log에 기록하여 과거 버전으로 복원할 수 있도록 한다.
SELECT 쿼리는 ReadView를 기준으로 현재 Row가 보여질 수 없는 경우, Undo Log를 따라가 과거 버전을 복원하여 보여준다.
트랜잭션이 ROLLBACK되면 Undo Log를 이용해 변경을 되돌릴 수 있고, COMMIT되면 변경 내용은 Redo Log와 함께 디스크에 영구 저장된다.
Undo Log
트랜잭션이 데이터를 변경(INSERT/UPDATE/DELETE)하기 전에
기존 값으로 복원할 수 있도록 따로 저장해두는 로그
모든 데이터 변경 전에는, 그 Row의 기존 값(이전 버전) 을 undo log에 저장한다.
트랜잭션이 데이터를 읽을 때, ReadView를 기준으로 현재 Row가 보여질 수 없는 경우, Undo Log를 따라가 과거 버전을 복원하여 보여준다.
undo log는 undo log segment 안에 존재하고 undo log segment는 rollback segment라는 더 큰 단위 안에 들어간다.
이 rollback segment는 undo tablespace에 저장한다.
rollback segment는 내부에 여러 undo slot을 가지고 있고, 각 트랜잭션은 1개 슬롯을 차지하여 undo log를 생성한다.
슬롯 수는 페이지 사이즈에 따라 정해지고,그 수만큼만 동시에 트랜잭션을 처리한다.
참고로 InnoDB는 내부적으로 데이터를 1 페이지 = 16KB (기본값) 로 저장한다.
InnoDB는 사용자에게 보이지 않지만 내부적으로 모든 row에 시스템 컬럼을 자동으로 추가한다.
| 컬럼 | 설명 |
| db_trx_id | 해당 row를 마지막으로 수정한 트랜잭션 id |
| db_roll_ptr | undo log를 가리키는 포인터 (이전 버전 복원용) |
| db_row_id | InnoDB가 내부적으로 부여하는 행 번호 (auto increment처럼 증가) 사용자가 PK를 정의하지 않았을 때, InnoDB가 자동으로 클러스터형 인덱스를 만들기 위해 필요. pk가 있을 경우는 인덱스에 포함되지 않는다. |
트랜잭션에서 조회할 때, InnoDB는 해당 row의 db_trx_id를 확인하여 현재 트랜잭션의 유효성 범위 내에 있는지 판단한다.
만약 해당 row가 보이면 안 되는 상태 (즉, 다른 트랜잭션에서 변경한 최신 버전) 이라면 db_roll_ptr를 따라 Undo Log로 이동하여 과거 버전의 데이터를 조회한다.
Undo Log와 DML 동작 원리
InnoDB는 디스크에 있는 데이터를 메모리(Bufffer Pool) 에 캐싱해두고 실제로는 대부분의 읽기/쓰기 작업을 메모리에서 처리 하는 구조를 가진다.
InnoDB는 1개의 데이터 페이지(16KB) 단위로 디스크에서 읽어온다.
어떤 Row 하나를 읽을 때도, 그 Row가 포함된 전체 페이지를 읽어와서 Buffer Pool에 올린다.
UPDATE 과정
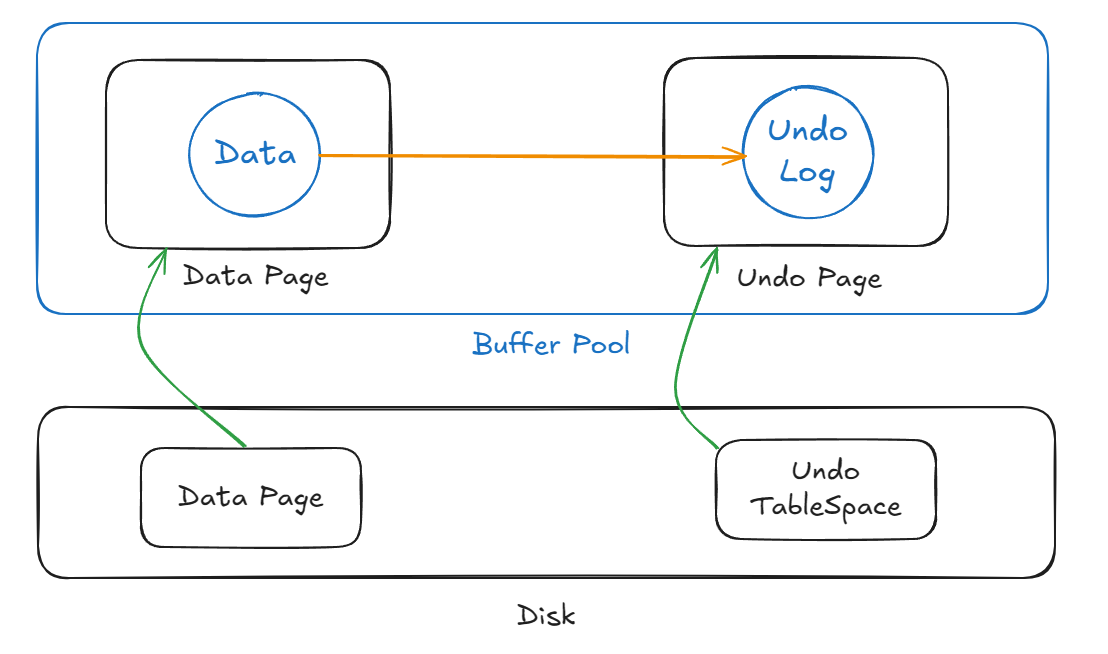
1. UPDATE 쿼리 실행
2. 변경할 Row가 포함된 페이지가 Buffer Pool에 있는지 확인
없으면 디스크에서 읽어서 Buffer Pool에 로딩
3. 기존 Row의 변경 전 데이터를 Undo Log에 기록
이 undo log 또한 disk Undo TableSpace에서 Buffer Pool로 로딩
트랜잭션이 Row의 일부만 변경하면 undo log에는 변경된 컬럼의 변경 전 값만 저장
4, Buffer Pool에서 데이터 수정
변경된 페이지는 Dirty Page로 표시
5. Buffer Pool의 Dirty Page는 COMMIT 여부와 무관하게 InnoDB 백그라운드 쓰레드에 의해 디스크로 flush
flush란 버퍼풀 안에서 변경된 데이터(dirty page)를 디스크에 반영하는 작업
INSERT 과정
INSERT 시에도, 데이터를 삽입할 위치에 해당하는 데이터 페이지가 존재하지 않으면 새로 생성하고 Buffer Pool에 로딩해야 한다.
InnoDB는 데이터를 개별 Row 단위로 관리하지 않고 페이지 단위로 관리하는 것을 항상 생각해야한다.
1. INSERT 쿼리 실행
2. 새로 삽입할 페이지가 Buffer Pool에 있는지 확인
없으면 디스크에서 로딩
3. Buffer Pool의 데이터 페이지에 새 Row 추가
4. Undo Log 생성 (rollback 시 이 Row 삭제할 수 있도록)
5. 데이터 페이지는 Dirty Page로 남아 있고 백그라운드 쓰레드가 디스크에 flush
Delete 과정
1. DELETE 쿼리 실행
2. 삭제 대상 Row가 포함된 페이지를 Buffer Pool에 로딩
3. 삭제될 Row 전체를 Undo Log에 저장
rollback 시 복원 + MVCC를 위해 필요(다른 트랜잭션이 과거 버전을 SELECT 할 수 있게)
4. Buffer Pool에서 해당 Row를 삭제 처리
Dirty Page로 표시
DELETE는 실제로 Row를 물리적으로 지우지 않고, 페이지 내부에서 삭제 플래그를 남긴다.
Row 하나 지우려고 페이지 전체를 재정렬하면 성능 저하가 발생하기 때문이다.
실제 삭제는 백그라운드에서 purge 쓰레드가 다음 조건을 보고 물리 삭제한다.
a. 해당 row를 참조하는 트랜잭션이 더 이상 없음
b. commit 완료
c. MVCC로 복원할 필요가 없음
5. Dirty Page는 백그라운드에서 디스크에 flush
purge란 InnoDB 스토리지 엔진이 다중 버전 동시성 제어(MVCC)나 롤백 작업에 더 이상 필요하지 않은 언두 로그와 삭제된 테이블 레코드를 정리하는 작업
Undo Log로 인해 발생할 수 있는 성능 이슈
대량 DELETE로 인한 undo log 폭증
delete from huge_table;수백만 row가 있는 테이블을 전체 삭제하는 예를 들면 모든 삭제 row가 undo log에 통째로 기록된다.
undo tablespace가 커지고 디스크 I/O 부하가 발생한다.
삭제를 긴 트랜잭션 하나로 몰지 않고 LIMIT으로 분할하여 반복 삭제한다.
트랜잭션을 오래 유지할 경우 purge가 지연된다.
한 세션에서 트랜잭션을 열고 오랜 시간동안 유지하는 경우 purge 쓰레드는 해당 트랜잭션이 commit될지 rollback될지 모르므로 undo log를 계속해서 쌓는다.
따라서 undo log가 쌓이기만 하고 정리가 되지 않아 history list가 증가하고 성능저하가 발생된다.
트랜잭션을 가능한 짧게 유지한다.
API 요청 등 네트워크 요청과 관련된 부분은 가능하면 트랜잭션 밖에서 수행하도록 한다.
이제, 이렇게 동작하는 MVCC 메커니즘이 어떻게 트랜잭션 격리 수준(Isolation Level)과 연결되어 락 없이 동시성을 해결하는지를 다음 글에서 정리할 예정이다.
Isolation Level - 트랜잭션 격리 수준 깊게 이해하기
InnoDB 스토리지 엔진을 사용하는 mysql 기준으로 정리한다. 먼저 MVCC와 undo log, read view에 대한 이해가 필요하다.https://cactuslog.tistory.com/39 MVCC 깊게 이해하기: Undo Log 기반 다중 버전 동시 제어의 원
cactuslog.tistory.com
'database' 카테고리의 다른 글
| Isolation Level - 트랜잭션 격리 수준 깊게 이해하기 (1) | 2025.04.12 |
|---|---|
| 트랜잭션과 ACID (0) | 2025.03.23 |
| ubuntu에 mysql 설치하기 (0) | 2024.11.18 |
| MySQL Error [1248]: Every derived table must have its own alias (0) | 2024.03.16 |
| MySQL Error [1093]: You can't specify target table 테이블명 for update in FROM clause (0) | 2024.03.16 |



